学途智助
首页
分类
标签
关于网站
登录
eeettt
2026-03-28
2
作者编辑
Mem0论文及源码解读:给你的大模型加上长期记忆
# Mem0论文及源码解读:给你的大模型加上长期记忆 > 原文链接:chrome-extension://namdombppngfekpbkmmaoighpkeommih/popup.html 本文是对《Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory》论文和Mem0核心开源代码的解读。具体使用方法可参考[Mem0实战指南](https://zhuanlan.zhihu.com/p/1904540128740868767)。 ## 0 引言目前大多数 AI 系统都存在一个大问题:它们的记忆能力有限,尤其是在长时间对话中,AI 容易忘记之前的信息,导致重复提问或错误的回答。 为了弥补这一缺陷,本文提出了Mem0,一种记忆架构,它能够动态地提取和整合对话中的关键信息,让 AI 系统能记住重要内容并跨会话持续对话。更进一步,还提出了Mem0g,它在 Mem0 的基础上加入了[图结构记忆](https://zhida.zhihu.com/search?content_id=257694227&content_type=Article&match_order=1&q=%E5%9B%BE%E7%BB%93%E6%9E%84%E8%AE%B0%E5%BF%86&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NzQ4MDY1MDMsInEiOiLlm77nu5PmnoTorrDlv4YiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTc2OTQyMjcsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.v0J31d_G97u5heB6rxZ0XDT6qcS7-dLX4WNLLpt7rn4&zhida_source=entity)(就是[知识图谱](https://zhida.zhihu.com/search?content_id=257694227&content_type=Article&match_order=1&q=%E7%9F%A5%E8%AF%86%E5%9B%BE%E8%B0%B1&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NzQ4MDY1MDMsInEiOiLnn6Xor4blm77osLEiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTc2OTQyMjcsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.xRA9zC_U-iWayj0_BEqeiOoFuBvcY5-TE1McuTyj6Ho&zhida_source=entity)),使得 AI 在处理复杂关系时更得心应手。 接下来,我们将结合论文介绍和源码实现介绍这两个架构的工作原理。 ## 1 Mem0架构工作原理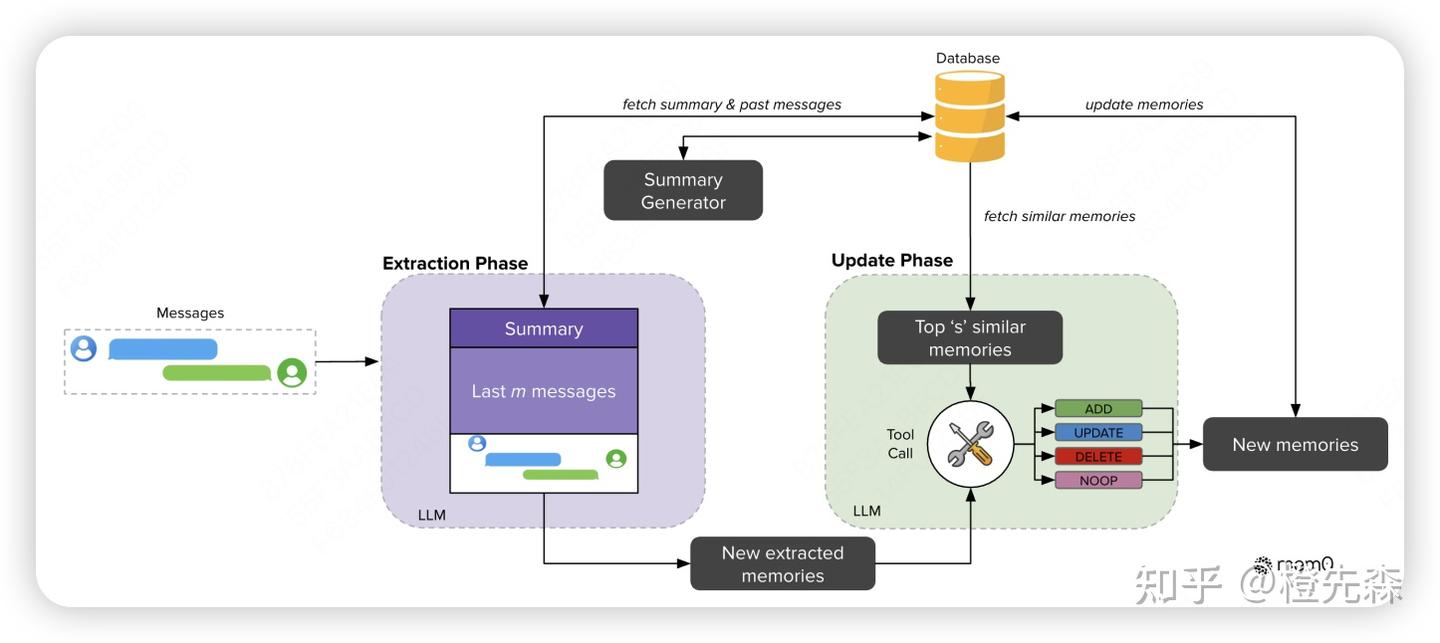Mem0框架图Mem0 的架构核心在于记忆提取与记忆更新机制,旨在确保 AI 系统能够动态地提取对话中的关键信息,并有效地更新其记忆库。这个过程分为两个主要阶段:记忆提取 和 记忆更新。 ## 1.1 Mem0记忆提取首先,当新的对话消息进入系统后,Mem0会通过一个异步摘要生成模块生成并存储一个会话摘要(S)。它的作用是概括整个对话的核心主题,从而为后续的记忆提取提供全局记忆。这个过程并不是一次性的,而是随着对话的进展持续进行更新。 ``` # mem0/memory/main.py - 记忆提取部分 def _create_procedural_memory(self, messages, metadata=None, prompt=None): """ # 异步摘要生成模块:创建程序化记忆(会话摘要) # 该函数接收对话消息,使用[LLM](https://zhida.zhihu.com/search?content_id=257694227&content_type=Article&match_order=1&q=LLM&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NzQ4MDY1MDMsInEiOiJMTE0iLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTc2OTQyMjcsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.g1jeLXwvynT4PSOF_H0dI1GWNG4Zag178Y65KrPu4bY&zhida_source=entity)生成一个摘要,并将其存储为特殊类型的记忆 Args: messages (list): 待处理的对话消息列表 metadata (dict): 存储元数据信息 prompt (str, optional): 自定义提示词,默认使用系统提示 """ logger.info("Creating procedural memory") # 1. 构建系统提示和用户消息,用于指导LLM生成摘要 parsed_messages = [ {"role": "system", "content": prompt or PROCEDURAL_MEMORY_SYSTEM_PROMPT}, *messages, { "role": "user", "content": "Create procedural memory of the above conversation.", }, ] try: # 2. 使用LLM生成对话的摘要记忆 procedural_memory = self.llm.generate_response(messages=parsed_messages) except Exception as e: logger.error(f"Error generating procedural memory summary: {e}") raise if metadata is None: raise ValueError("Metadata cannot be done for procedural memory.") # 3. 标记这是一个程序化记忆(会话摘要) metadata["memory_type"] = MemoryType.PROCEDURAL.value # 4. 为摘要生成向量嵌入 embeddings = self.embedding_model.embed(procedural_memory, memory_action="add") # 5. 创建记忆并存储在[向量数据库](https://zhida.zhihu.com/search?content_id=257694227&content_type=Article&match_order=1&q=%E5%90%91%E9%87%8F%E6%95%B0%E6%8D%AE%E5%BA%93&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NzQ4MDY1MDMsInEiOiLlkJHph4_mlbDmja7lupMiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTc2OTQyMjcsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.qUZx_ko3_TQJWBgJMPH5AtCD55vXnGWtoOxqsn7Asis&zhida_source=entity)中 memory_id = self._create_memory(procedural_memory, {procedural_memory: embeddings}, metadata=metadata) capture_event("mem0._create_procedural_memory", self, {"memory_id": memory_id, "sync_type": "sync"}) # 6. 返回创建的记忆结果 result = {"results": [{"id": memory_id, "memory": procedural_memory, "event": "ADD"}]} return result ``` 这里使用的PROCEDURAL_MEMORY_SYSTEM_PROMPT很长,目前看到的很多agent的prompt都是非常结构化非常长的文本,说明prompt engineering还是很重要的。。。 ``` PROCEDURAL_MEMORY_SYSTEM_PROMPT = """ You are a memory summarization system that records and preserves the complete interaction history between a human and an AI agent. You are provided with the agent’s execution history over the past N steps. Your task is to produce a comprehensive summary of the agent's output history that contains every detail necessary for the agent to continue the task without ambiguity. **Every output produced by the agent must be recorded verbatim as part of the summary.** ### Overall Structure: - **Overview (Global Metadata):** - **Task Objective**: The overall goal the agent is working to accomplish. - **Progress Status**: The current completion percentage and summary of specific milestones or steps completed. - **Sequential Agent Actions (Numbered Steps):** Each numbered step must be a self-contained entry that includes all of the following elements: 1. **Agent Action**: - Precisely describe what the agent did (e.g., "Clicked on the 'Blog' link", "Called API to fetch content", "Scraped page data"). - Include all parameters, target elements, or methods involved. 2. **Action Result (Mandatory, Unmodified)**: - Immediately follow the agent action with its exact, unaltered output. - Record all returned data, responses, HTML snippets, JSON content, or error messages exactly as received. This is critical for constructing the final output later. 3. **Embedded Metadata**: For the same numbered step, include additional context such as: - **Key Findings**: Any important information discovered (e.g., URLs, data points, search results). - **Navigation History**: For browser agents, detail which pages were visited, including their URLs and relevance. - **Errors & Challenges**: Document any error messages, exceptions, or challenges encountered along with any attempted recovery or troubleshooting. - **Current Context**: Describe the state after the action (e.g., "Agent is on the blog detail page" or "JSON data stored for further processing") and what the agent plans to do next. ### Guidelines: 1. **Preserve Every Output**: The exact output of each agent action is essential. Do not paraphrase or summarize the output. It must be stored as is for later use. 2. **Chronological Order**: Number the agent actions sequentially in the order they occurred. Each numbered step is a complete record of that action. 3. **Detail and Precision**: - Use exact data: Include URLs, element indexes, error messages, JSON responses, and any other concrete values. - Preserve numeric counts and metrics (e.g., "3 out of 5 items processed"). - For any errors, include the full error message and, if applicable, the stack trace or cause. 4. **Output Only the Summary**: The final output must consist solely of the structured summary with no additional commentary or preamble. ### Example Template: /``` ## Summary of the agent's execution history **Task Objective**: Scrape blog post titles and full content from the OpenAI blog. **Progress Status**: 10/%/ complete — 5 out of 50 blog posts processed. 1. **Agent Action**: Opened URL "https://openai.com" **Action Result**: "HTML Content of the homepage including navigation bar with links: 'Blog', 'API', 'ChatGPT', etc." **Key Findings**: Navigation bar loaded correctly. **Navigation History**: Visited homepage: "https://openai.com" **Current Context**: Homepage loaded; ready to click on the 'Blog' link. 2. **Agent Action**: Clicked on the "Blog" link in the navigation bar. **Action Result**: "Navigated to 'https://openai.com/blog/' with the blog listing fully rendered." **Key Findings**: Blog listing shows 10 blog previews. **Navigation History**: Transitioned from homepage to blog listing page. **Current Context**: Blog listing page displayed. 3. **Agent Action**: Extracted the first 5 blog post links from the blog listing page. **Action Result**: "[ '/blog/chatgpt-updates', '/blog/ai-and-education', '/blog/openai-api-announcement', '/blog/gpt-4-release', '/blog/safety-and-alignment' ]" **Key Findings**: Identified 5 valid blog post URLs. **Current Context**: URLs stored in memory for further processing. 4. **Agent Action**: Visited URL "https://openai.com/blog/chatgpt-updates" **Action Result**: "HTML content loaded for the blog post including full article text." **Key Findings**: Extracted blog title "ChatGPT Updates – March 2025" and article content excerpt. **Current Context**: Blog post content extracted and stored. 5. **Agent Action**: Extracted blog title and full article content from "https://openai.com/blog/chatgpt-updates" **Action Result**: "{ 'title': 'ChatGPT Updates – March 2025', 'content': 'We\'re introducing new updates to ChatGPT, including improved browsing capabilities and memory recall... (full content)' }" **Key Findings**: Full content captured for later summarization. **Current Context**: Data stored; ready to proceed to next blog post. ... (Additional numbered steps for subsequent actions) /``` """ ``` 当有新的对话消息进入系统时,Mem0 会从数据库中取出本次对话的 会话摘要(S),帮助系统理解整个对话的全局上下文。 此外,Mem0 还会使用一个 最近消息窗口,即最近的若干条消息(由超参数 m 控制),以便提取出更多的细节上下文信息。 Mem0 会将 会话摘要 和 最近消息 结合起来(很常见的全局和局部信息结合的思想),与当前的新消息(用户和助手的最新一轮对话)一起,生成一个 综合提示(P)。这个提示会被送入一个提取函数,通过大语言模型(LLM)来处理和提取出一组 候选记忆(Ω)。这些候选记忆是与当前对话相关的关键信息,用于后续更新知识库中的记忆。 ``` # mem0/memory/main.py - 提取记忆事实的相关代码 def _add_to_vector_store(self, messages, metadata, filters, infer): """ 提取记忆功能:处理消息并提取记忆事实 该函数实现了记忆的提取和存储过程 """ # 如果不需要生成记忆片段,则直接存储原始消息(按原样存储) if not infer: returned_memories = [] for message in messages: if message["role"] != "system": message_embeddings = self.embedding_model.embed(message["content"], "add") memory_id = self._create_memory(message["content"], message_embeddings, metadata) returned_memories.append({"id": memory_id, "memory": message["content"], "event": "ADD"}) return returned_memories # 1. 解析对话消息,形成上下文 parsed_messages = parse_messages(messages) # 2. 构建提示,使用最近消息窗口作为上下文 if self.config.custom_fact_extraction_prompt: system_prompt = self.config.custom_fact_extraction_prompt user_prompt = f"Input:\n{parsed_messages}" else: system_prompt, user_prompt = get_fact_retrieval_messages(parsed_messages) # 提取记忆的system prompt自己看源码吧,比较长这里就不贴了 # 3. 使用LLM提取事实(候选记忆) response = self.llm.generate_response( messages=[ {"role": "system", "content": system_prompt}, {"role": "user", "content": user_prompt}, ], response_format={"type": "json_object"}, ) # 4. 解析LLM输出,获取候选记忆 try: response = remove_code_blocks(response) new_retrieved_facts = json.loads(response)["facts"] # 候选记忆列表 except Exception as e: logging.error(f"Error in new_retrieved_facts: {e}") new_retrieved_facts = [] # 5. 准备从向量数据库检索相似记忆,以便后续进行更新决策 retrieved_old_memory = [] new_message_embeddings = {} for new_mem in new_retrieved_facts: # 为每个候选记忆生成向量嵌入 messages_embeddings = self.embedding_model.embed(new_mem, "add") new_message_embeddings[new_mem] = messages_embeddings # 检索向量数据库中与候选记忆语义相似的现有记忆 existing_memories = self.vector_store.search( query=new_mem, vectors=messages_embeddings, limit=5, filters=filters, ) # 收集相似的现有记忆 for mem in existing_memories: retrieved_old_memory.append({"id": mem.id, "text": mem.payload["data"]}) ``` ## 1.2 Mem0记忆更新记忆提取后,Mem0 会进入 记忆更新 阶段。在这个阶段,系统会将刚提取的候选记忆组与现有记忆进行对比,确保它们的一致性并避免冗余。为此,Mem0 首先会检索出与候选记忆语义最相似的若干个现有记忆(向量数据库向量检索)。然后通过function call的形式调用记忆更新工具来更新记忆。工具有4个: - 添加(ADD):当没有语义相似的记忆时,将新记忆添加到知识库。 - 更新(UPDATE):当现有记忆与新记忆有部分重叠时,更新现有记忆,以纳入新信息。 - 删除(DELETE):当现有记忆与新记忆存在冲突时,删除旧记忆。 - 无操作(NOOP):当新记忆与现有记忆一致时,保持现有记忆不变。 当现有记忆与新提取的候选记忆存在冲突时,Mem0 会决定是否删除、更新或添加新记忆。 ``` # mem0/memory/main.py - 记忆更新部分 # 继续_add_to_vector_store函数中的记忆更新流程... # 使用LLM决定每个记忆的操作(添加/更新/删除/无操作) try: response: str = self.llm.generate_response( messages=[{"role": "user", "content": function_calling_prompt}], response_format={"type": "json_object"}, ) except Exception as e: logging.error(f"Error in new memory actions response: {e}") response = "" # 解析LLM的决策结果 try: response = remove_code_blocks(response) new_memories_with_actions = json.loads(response) except Exception as e: logging.error(f"Invalid JSON response: {e}") new_memories_with_actions = {} # 根据决策结果执行相应的记忆操作 returned_memories = [] try: for resp in new_memories_with_actions.get("memory", []): logging.info(resp) try: if not resp.get("text"): logging.info("Skipping memory entry because of empty `text` field.") continue # 添加新记忆 elif resp.get("event") == "ADD": memory_id = self._create_memory( data=resp.get("text"), existing_embeddings=new_message_embeddings, metadata=deepcopy(metadata), ) returned_memories.append( { "id": memory_id, "memory": resp.get("text"), "event": resp.get("event"), } ) # 更新现有记忆 elif resp.get("event") == "UPDATE": self._update_memory( memory_id=temp_uuid_mapping[resp["id"]], data=resp.get("text"), existing_embeddings=new_message_embeddings, metadata=deepcopy(metadata), ) returned_memories.append( { "id": temp_uuid_mapping[resp.get("id")], "memory": resp.get("text"), "event": resp.get("event"), "previous_memory": resp.get("old_memory"), } ) # 删除现有记忆 elif resp.get("event") == "DELETE": self._delete_memory(memory_id=temp_uuid_mapping[resp.get("id")]) returned_memories.append( { "id": temp_uuid_mapping[resp.get("id")], "memory": resp.get("text"), "event": resp.get("event"), } ) # 无需操作 elif resp.get("event") == "NONE": logging.info("NOOP for Memory.") except Exception as e: logging.error(f"Error in new_memories_with_actions: {e}") except Exception as e: logging.error(f"Error in new_memories_with_actions: {e}") return returned_memories ``` 这一机制的核心在于保持记忆库的 一致性并且避免冗余信息。 保存好记忆后,检索就方便了,直接向量数据库语义相似度取top-k个最相似的记忆即可。 ``` # mem0/memory/main.py - 会话摘要检索部分 def search(self, query, user_id=None, agent_id=None, run_id=None, limit=100, filters=None): """ 搜索记忆函数:从记忆库中搜索相关信息 该函数会搜索包括会话摘要在内的各类记忆 Args: query (str): 搜索查询内容 user_id, agent_id, run_id: 用于过滤的ID limit: 结果数量上限 filters: 额外的过滤条件 """ filters = filters or {} if user_id: filters["user_id"] = user_id if agent_id: filters["agent_id"] = agent_id if run_id: filters["run_id"] = run_id if not any(key in filters for key in ("user_id", "agent_id", "run_id")): raise ValueError("One of the filters: user_id, agent_id or run_id is required!") capture_event( "mem0.search", self, {"limit": limit, "version": self.api_version, "keys": list(filters.keys()), "sync_type": "sync"}, ) # 将向量存储和图存储的搜索并行执行以提高效率 with concurrent.futures.ThreadPoolExecutor() as executor: # 1. 从向量数据库中搜索记忆(包括会话摘要) future_memories = executor.submit(self._search_vector_store, query, filters, limit) # 2. 如果启用了图存储,同时在图中搜索 future_graph_entities = ( executor.submit(self.graph.search, query, filters, limit) if self.enable_graph else None ) concurrent.futures.wait( [future_memories, future_graph_entities] if future_graph_entities else [future_memories] ) # 获取搜索结果 original_memories = future_memories.result() graph_entities = future_graph_entities.result() if future_graph_entities else None # 返回搜索结果,包括会话摘要和其他记忆 if self.enable_graph: return {"results": original_memories, "relations": graph_entities} # API版本兼容处理 if self.api_version == "v1.0": warnings.warn( "The current get_all API output format is deprecated. " "To use the latest format, set `api_version='v1.1'`. " "The current format will be removed in mem0ai 1.1.0 and later versions.", category=DeprecationWarning, stacklevel=2, ) return original_memories else: return {"results": original_memories} def _search_vector_store(self, query, filters, limit): """ 向量存储搜索功能:基于语义相似度搜索记忆 该函数实现了实际的向量检索逻辑 """ # 1. 将查询转换为向量表示 embeddings = self.embedding_model.embed(query, "search") # 2. 在向量数据库中搜索相似的记忆,包括会话摘要 memories = self.vector_store.search(query=query, vectors=embeddings, limit=limit, filters=filters) # 需要排除的元数据键 excluded_keys = { "user_id", "agent_id", "run_id", "hash", "data", "created_at", "updated_at", "id", } # 3. 格式化搜索结果,包含相似度分数 original_memories = [ { **MemoryItem( id=mem.id, memory=mem.payload["data"], hash=mem.payload.get("hash"), created_at=mem.payload.get("created_at"), updated_at=mem.payload.get("updated_at"), score=mem.score, # 包含相似度分数 ).model_dump(), **{key: mem.payload[key] for key in ["user_id", "agent_id", "run_id"] if key in mem.payload}, **( {"metadata": {k: v for k, v in mem.payload.items() if k not in excluded_keys}} if any(k for k in mem.payload if k not in excluded_keys) else {} ), } for mem in memories ] return original_memories ``` ## 2 Mem0g架构工作原理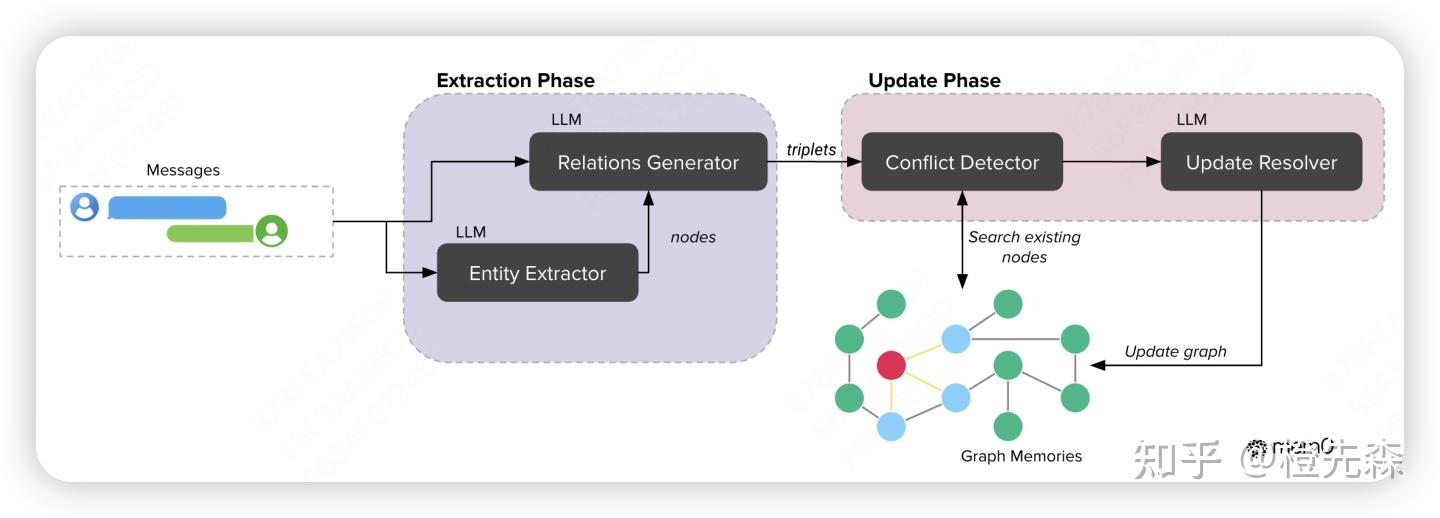Mem0g框架图在 Mem0 的基础上,Mem0g 引入了传统知识图谱的思想来增强其对复杂关系的处理能力。与 Mem0 主要通过文本和摘要来管理记忆不同,Mem0g 通过三元组方式将记忆存储为头节点、尾节点和关系边的图,这种结构能更好地捕捉了不同实体之间的关系。同样是两个阶段(提取和更新)。 ## 2.1 Mem0g记忆提取Mem0g 采用了图结构来表示和处理实体和关系。Mem0g 首先通过一个实体提取模块从对话中识别出所有相关的实体(例如人物、地点、事件等)及实体类别。随后,系统会通过关系生成模块根据对话上下文建立实体之间的关系,形成一组三元组(如实体 A 、实体 B及关系 R)。这些三元组也就组成了一个记忆知识图谱。这里Mem0g在抽取实体和关系的时候就是用大模型+prompt完成,没有用传统nlp中实体识别或者关系抽取的方法。并且,它是采用两阶段完成,即先实体抽取,再关系生成。传统nlp时代(也称BERT时代)也有很多一步同时生成实体和关系的方法。(ps:我的博士研究方向就是知识图谱构建,有点怀念那个没有被大模型统治的时代hhh) ``` # mem0/memory/graph_memory.py - 知识图谱记忆模块 class MemoryGraph: def __init__(self, config: MemoryConfig = MemoryConfig()): """ 知识图谱记忆模块初始化 负责实体提取、关系生成和图谱维护 """ self.config = config # 初始化图数据库存储 self.graph_store = GraphStoreFactory.create( self.config.graph_store.provider, self.config.graph_store.config ) # 初始化LLM用于实体和关系提取 self.llm = LlmFactory.create(self.config.llm.provider, self.config.llm.config) # 初始化嵌入模型用于语义相似度计算 self.embedding_model = EmbedderFactory.create( self.config.embedder.provider, self.config.embedder.config, self.config.vector_store.config, ) def add(self, message, filters=None): """ 向知识图谱添加新信息 实现从文本中提取实体和关系并构建知识图谱 """ filters = filters or {} # 1. 使用LLM提取实体 # 实体提取模块:从文本中识别相关实体及其类别 entity_prompt = self._get_entity_extraction_prompt(message) entity_response = self.llm.generate_response( messages=[{"role": "user", "content": entity_prompt}], response_format={"type": "json_object"}, ) try: # 解析LLM返回的实体列表 entity_response = remove_code_blocks(entity_response) entity_data = json.loads(entity_response) entities = entity_data.get("entities", []) # 如果没有提取到实体,直接返回 if not entities: return [] # 2. 使用LLM生成实体间关系 # 关系生成模块:根据上下文建立实体之间的语义关系 relation_prompt = self._get_relation_extraction_prompt(message, entities) relation_response = self.llm.generate_response( # 核心还是构建prompt+调用大模型的方式 messages=[{"role": "user", "content": relation_prompt}], response_format={"type": "json_object"}, ) # 解析LLM返回的关系列表 relation_response = remove_code_blocks(relation_response) relation_data = json.loads(relation_response) relations = relation_data.get("relations", []) # 3. 将实体和关系添加到图数据库中 added_entities = [] for relation in relations: # 处理头实体 source_entity = relation.get("source") source_entity_type = relation.get("source_type") # 处理尾实体 target_entity = relation.get("target") target_entity_type = relation.get("target_type") # 处理关系 relationship = relation.get("relationship") # 将实体和关系信息添加到图数据库 if source_entity and target_entity and relationship: # 为实体和关系生成向量嵌入,用于后续相似性检索 source_entity_embeddings = self.embedding_model.embed(source_entity, "add") target_entity_embeddings = self.embedding_model.embed(target_entity, "add") # 添加到图数据库并记录结果 result = self.graph_store.add_triple( source=source_entity, source_type=source_entity_type, relationship=relationship, target=target_entity, target_type=target_entity_type, source_embedding=source_entity_embeddings, target_embedding=target_entity_embeddings, metadata=filters ) added_entities.append({ "source": source_entity, "source_type": source_entity_type, "relationship": relationship, "destination": target_entity, "destination_type": target_entity_type }) return added_entities except Exception as e: logger.error(f"Error in entity/relation extraction: {e}") return [] def _get_entity_extraction_prompt(self, message): """ 生成实体提取的提示词 指导LLM识别文本中的各类实体 """ return """You are an entity extraction system. Your task is to identify the most important entities in the given text. An entity can be a person, place, organization, product, or concept. For each entity, provide its type. Format your response as a JSON object with a single key "entities", containing a list of entity objects. Each entity object should have "name" (the entity) and "type" fields. Here is the text to analyze: /``` {message} /``` JSON Response: """.format(message=message) def _get_relation_extraction_prompt(self, message, entities): """ 生成关系提取的提示词 指导LLM识别已提取实体之间的关系 """ entity_names = [e.get("name") for e in entities] entity_str = ", ".join(entity_names) return """You are a relationship extraction system. Your task is to identify meaningful relationships between the entities in the given text. Text: /``` {message} /``` Entities: {entities} For each relationship you identify, specify: 1. The source entity 2. The type of the source entity 3. The relationship (a verb or phrase describing how entities are connected) 4. The target entity 5. The type of the target entity Only create relationships that are explicitly or strongly implied in the text. Format your response as a JSON object with a single key "relations", containing a list of relationship objects. JSON Response: """.format(message=message, entities=entity_str) ``` ## 2.2 Mem0g记忆更新Mem0g 通过 图数据库 Neo4j进行节点和边的检索。具体来说,Mem0g 会计算新提取的实体与现有节点之间的语义相似度,并根据阈值决定是否更新或添加新的节点和关系。对图的操作(其实就是修改数据库中的三元组信息)也是通过function call的形式完成,具体tool和Mem0类似: - 添加(ADD):当新信息对应的实体和关系在图中没有对应节点时,Mem0g 会创建新的节点并建立关系。 - 更新(UPDATE):当现有图中的节点与新信息重合时,Mem0g 会通过更新节点属性(时间戳)来增强现有记忆。 - 删除(DELETE):如果新提取的信息与现有关系发生冲突,Mem0g 会删除这些冲突的关系,确保图结构的一致性。 - 无操作(NOOP):如果新信息与现有记忆一致,则不做任何操作,避免不必要的更新。 Mem0g 的 记忆检索功能 则是其与 Mem0 另一个显著的区别点。Mem0g 在处理查询时,采用了 双重检索策略,一方面是基于 实体 的检索,首先通过识别查询中的关键实体并在图中找到相应节点,之后探索这些节点的关联关系及对应的尾实体。另一方面,Mem0g 采用 语义三元组检索,即通过将整个查询转换为一个 向量表示,与图中的三元组进行匹配。(就是两种检索策略叠加使用,以期获得更全面的信息) ``` # mem0/memory/graph_memory.py - 知识图谱记忆检索功能 def search(self, query, filters=None, limit=20): """ 图谱记忆检索功能 实现双重检索策略:基于实体检索 + 语义三元组检索 Args: query: 用户查询文本 filters: 过滤条件 limit: 返回结果数量限制 """ filters = filters or {} results = [] try: # 1. 基于实体的检索策略 # 首先识别查询中的实体,然后在图中查找这些实体的关系 # 1.1 从查询中提取实体 entity_prompt = self._get_entity_extraction_prompt(query) entity_response = self.llm.generate_response( messages=[{"role": "user", "content": entity_prompt}], response_format={"type": "json_object"}, ) entity_response = remove_code_blocks(entity_response) entity_data = json.loads(entity_response) entities = entity_data.get("entities", []) # 1.2 如果查询中有实体,在图中检索相关实体和关系 if entities: entity_names = [e.get("name") for e in entities] # 以并行方式为每个实体检索关联关系 for entity_name in entity_names: # 查找该实体作为源节点的关系 source_relations = self.graph_store.search_by_source( source=entity_name, metadata=filters, limit=limit ) # 查找该实体作为目标节点的关系 target_relations = self.graph_store.search_by_target( target=entity_name, metadata=filters, limit=limit ) # 合并关系结果 entity_relations = source_relations + target_relations results.extend(entity_relations) # 2. 语义三元组检索策略 # 将查询转换为向量,然后在图中查找语义相似的三元组 # 2.1 为查询生成向量嵌入 query_embedding = self.embedding_model.embed(query, "search") # 2.2 在图中进行语义相似度搜索 semantic_results = self.graph_store.search_by_vector( vector=query_embedding, metadata=filters, limit=limit ) # 将语义搜索结果添加到最终结果中 results.extend(semantic_results) # 3. 结果去重和格式化 # 由于两种检索策略可能返回重复的三元组,需要去重 unique_results = [] seen_ids = set() for result in results: # 生成唯一标识,避免重复 result_id = f"{result.get('source')}-{result.get('relationship')}-{result.get('target')}" if result_id not in seen_ids: seen_ids.add(result_id) # 格式化结果 formatted_result = { "source": result.get("source"), "source_type": result.get("source_type"), "relationship": result.get("relationship"), "destination": result.get("target"), "destination_type": result.get("target_type"), "confidence": result.get("score", 1.0) if "score" in result else 1.0 } unique_results.append(formatted_result) # 根据相似度或置信度排序结果 unique_results.sort(key=lambda x: x.get("confidence", 0), reverse=True) # 限制返回结果数量 return unique_results[:limit] except Exception as e: logger.error(f"Error in graph memory search: {e}") return [] ``` ## 3 实验分析## 3.1 主实验在LOCOMO 数据集上对 Mem0 和 Mem0g 进行了评估,baseline包括多种现有的记忆增强系统。测试主要包括 单跳、多跳、开放域 和 时间推理 四种问题类型。 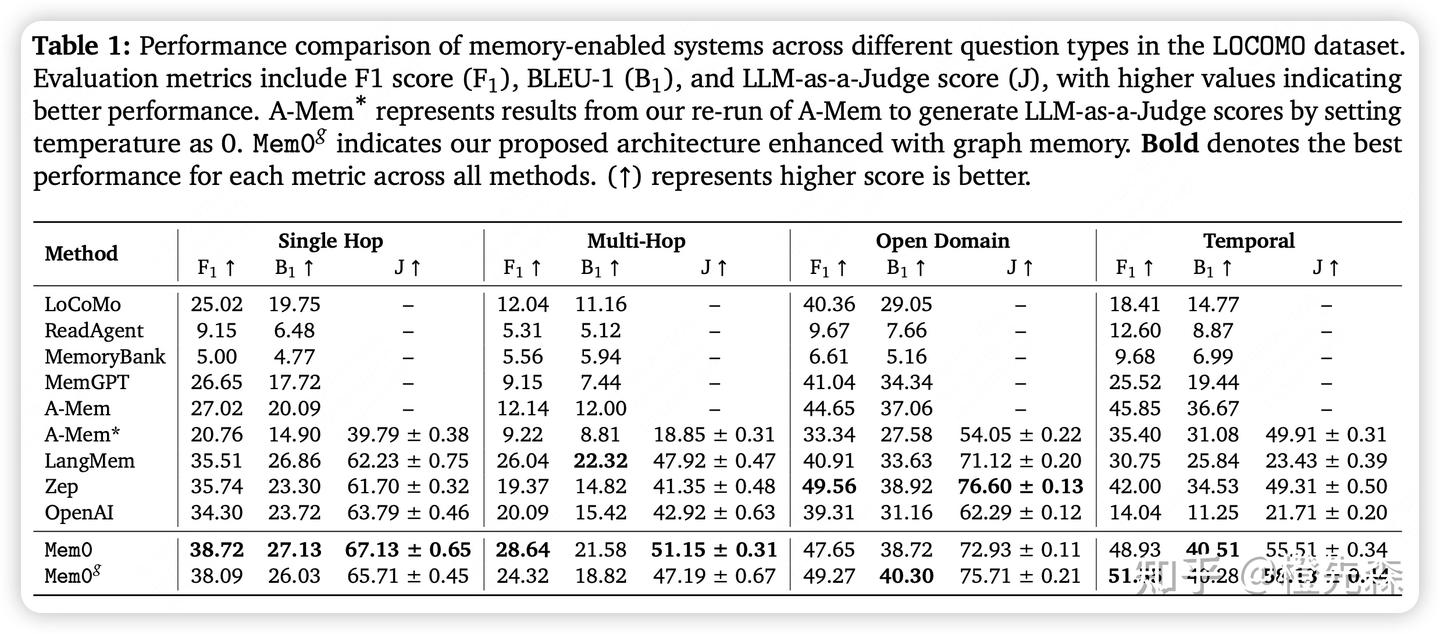主实验从上图可以看到,效果确实不错。值得注意的一点是,用了知识图谱的方法并不一定比直接向量检索的方法好,太真实了hhh。 ## 3.2 效率实验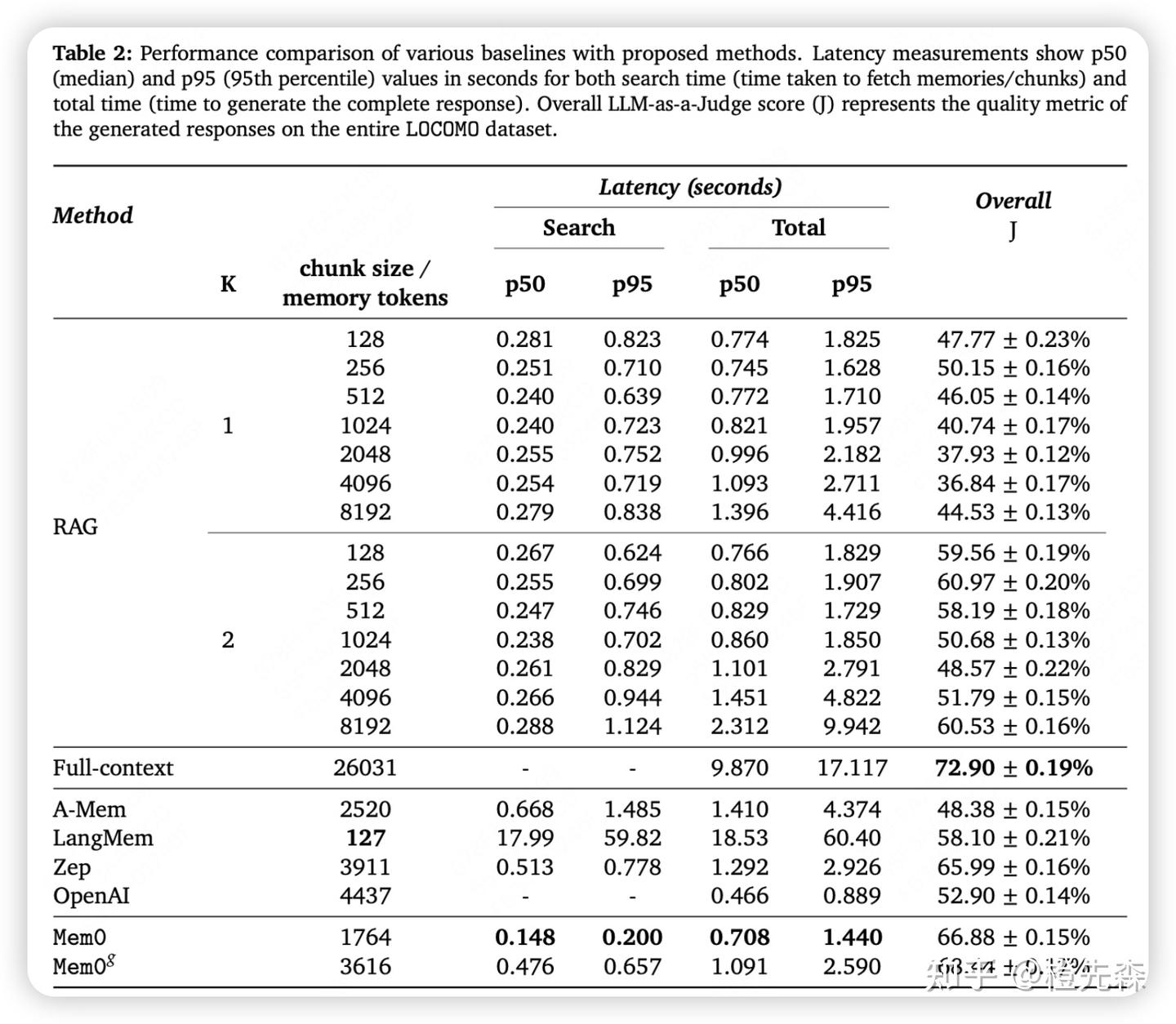效率实验在计算效率方面,Mem0 和 Mem0g 都显著优于全上下文处理方法,尤其是在响应时间和 p95 上,二者分别减少了 91% 和 85% 的延迟。此外,Mem0g 在存储效率上略有增加,因为其图结构需要更多的内存空间。 ## 总结本文基于mem0的[paper](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2504.19413)和[开源项目源码](https://link.zhihu.com/?target=https%3A//github.com/mem0ai/mem0)介绍了 Mem0 和 Mem0g 两种记忆架构。整体感觉没有特别大的创新,但是效果和计算效率都很好,实用性很强,比那些包装的很好,看似很创新实则效果一坨的paper还是好很多的hhh。 欢迎大家指正错误,点点关注,一起学习~
算法
赞
博客信息
作者
eeettt
发布日期
2026-03-28
其他信息 : 其他三字母的人名首字母都是其他同学发布的哦

